Basic idea is to have a workflow where feedback is instantanous by the build system, have warning set to maximum, eventually perform lint checks and dynamic memory allocation checks with valgrind.
These features may already exist in various commercial tools. This is not about that and instead this serves as a my go-to memo to know for future reference.
1) tup
Tup is a build system. Eeach folder can have it's own tupfile. tuplfile(s) can have global (or specific) tuprules, macros can be defined in tuprules, its an alternative to make, not better but different.
Note:
On linux it uses FUSE to monitor changes in the filesystem Does not work with windows well on this part.
You start the monitor with tup monitor -a and every update, change it will run to the foreground (can also be demonised)
Before wiritng the files you do a tup init in your folder. There it will create a hidden directory similar to the .git directory. There it will store the database that will keep track of dependences, files,and relationships.
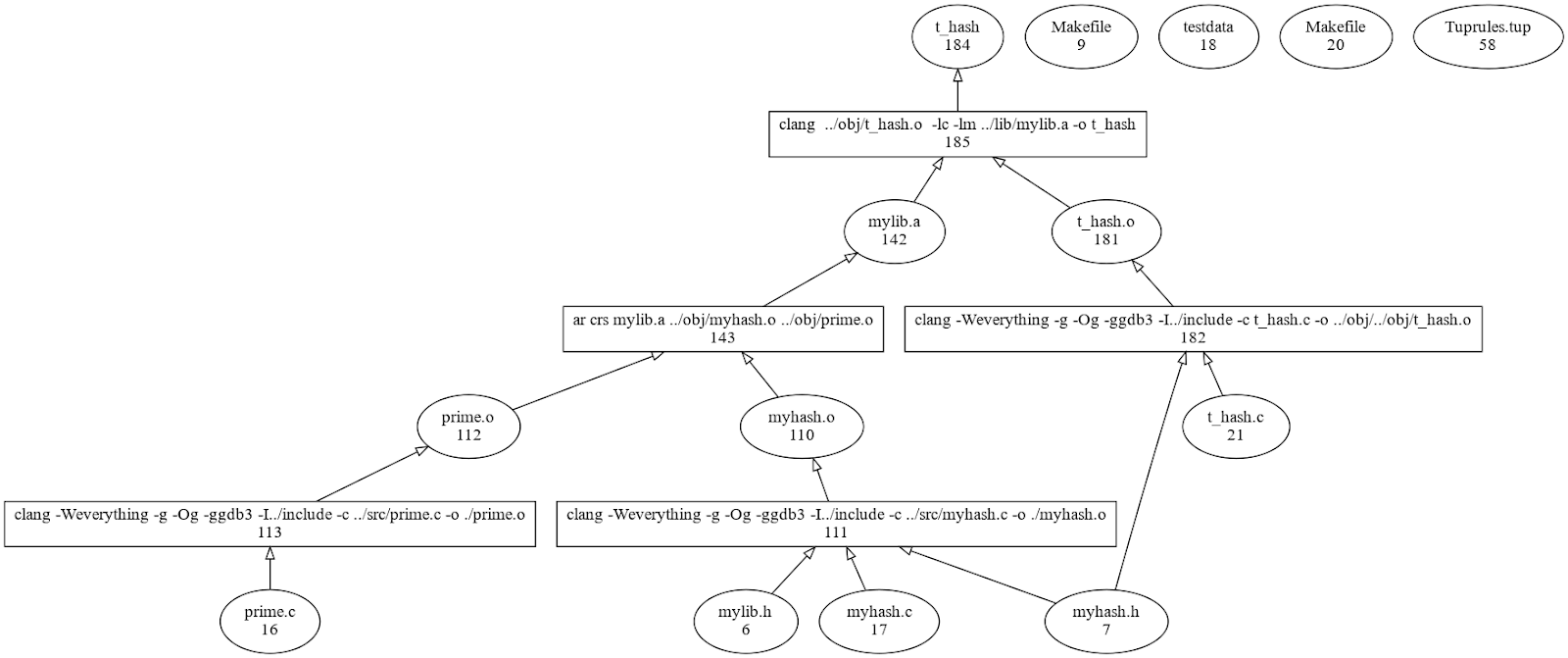
Layout of library project:
├── Tuprules.tup
├── include -here is where function prototypes where #includes
│ ├── myhash.h are used in the src directory (src depends on include)
│ └── mylib.h
├── lib -the lib directory is where the archive file is done before the linking
│ ├── Makefile -stage the lib directory is where your library consisting of
│ ├── Tupfile a number of obj files are stred in a single archive file
│ └── mylib.a (lib depends on obj)
├── obj -the object file directory is where files are output based
│ ├── Tupfile on the compilation phase. Files which compile should end up here to
│ ├── myhash.o later be used for the lib folder (obj depends on src)
│ ├── prime.o
│ └── t_hash.o
├── src -source files excluding headers (depends on include)
│ ├── myhash.c
│ └── prime.c
├── test -test directory to make sure everything works as it should.
│ ├── Makefile This should serve as a place to test all functionality of the library
│ ├── Tupfile and it's functions. Crash tests, should be done here.
│ ├── t_hash (depends on lib, obj - partially)
│ ├── t_hash.c
└── testdata
Basic syntax for a tupfile
Rule set situated in the top directory
#Variables start with & - keeping directories here
&libdir = include/
&objdir = obj/
#CFLAGS are appended with +=
CFLAGS += -Weverything
CFLAGS += -g
CFLAGS += -Og
CFLAGS += -ggdb3
#!macros for use in other Tupfiles - instead of typing the command to archive to compile, etc we can set up a macro
!cc = |> clang $(CFLAGS) -I&(libdir) -c %f -o &(objdir)/%o |> %B.o
!ar = |> ar crs %o %f |>
a) lib/Tupfile will include the rules on line 1
include_rules
: ../obj/*.o |> !ar |> mylib.a
Format of the last line is like this: (copy paste from man page)
: [foreach] [inputs] [ | order-only inputs] |> command |> [outputs] [ | extra outputs] [] [{bin}]
The :-rules are the primary means of creating commands, and are denoted by the fact that the ':' character appears in the first column of the Tupfile. The syntax is supposed to look somewhat like a pipeline, in that the input files on the left go into the command in the middle, and the output files come out on the right.
PS: Globbing does not match directories
b) second created Tupfile was in obj/Tupfile
include_rules
: foreach ../src/*.c |> !cc |>
c) third file is in tests/Tupfile
include_rules
CXFLAGS += -lc
CXFLAGS += -lm
CXFLAGS += ../lib/mylib.a
: *.c |> !cc |> ../obj/t_hash.o
: ../obj/t_hash.o | ../lib/mylib.a |> clang %f $(CXFLAGS) -o t_hash |> %B
This was more time consuming but the firs rule is to have the t_hash.o file which will become the test has program then have that and the library .a be the input to clang The pipe is "order-only inputs
These are also used as inputs for the command, but will not appear in any of the %-flags. They are separated from regular inputs by use of the '|' character. In effect, these can be used to specify additional inputs to a command that shouldn't appear on the command line. "
By the way flags:
%f The filename from the "inputs" section. This includes the path and extension.
%o The name of the output file(s)
%B Like %b, but strips the extension.
Sample output of monitor

The end strucutre looks like this:

2) lldb - more to the point and in a hurry
* breakpoints can't be set on line number as far as i can tell says it's pending
In either case use br set -n function name or br set -r regex for function name
* n for next , s for step
* br l - list breakpoints
* br del - delete them
* me read
-fX for hex uppercase -c25 25 lines I think -s8 - for bytes 8 bytes --force if it says it does not display more than 1024 bytes of memory
* bt to view stack
* frame variables to view what varaibles were assigned and their entry points
(lldb)
Process 27249 stopped
* thread #1, name = 't_hash', stop reason = step over
frame #0: 0x00005555555554bc t_hash`h_search(hTable=0x0000555555559260, key="400") at myhash.c:134:30
131 else {
132 // looking for the key inside the next element of the linked list
133 char* keyAtNextValue = hTable->h_items[resultHash]->h_next->h_key;
-> 134 while( nextValue->h_next != NULL) {
135 fprintf(stderr, "Found a collision, traversing Linked list at address %p, key is: %s",
136 nextValue, nextValue);
137 nextValue += 1;
(lldb) print nextValue
(HashNode *) $0 = 0x00005555555592e0
(lldb) br l
Current breakpoints:
1: name = 'h_search', locations = 1, resolved = 1, hit count = 1
1.1: where = t_hash`h_search + 17 at myhash.c:97:39, address = 0x0000555555555401, resolved, hit count = 1
(lldb) print *nextValue
(HashNode) $1 = {
h_next = 0x0000000000000000
h_key = 0x0000555555559300 "400"
h_value = 0x0000555555559320 "101"
}
(lldb) print *nextValue->h_next
error: Couldn't apply expression side effects : Couldn't dematerialize a result variable: couldn't read its memory
(lldb) print nextValue->h_next
(HashNode *) $3 = 0x0000000000000000
(lldb) print *nextValue->h_key
(char) $4 = '4'
(lldb) print nextValue->h_key
(char *) $5 = 0x0000555555559300 "400"
(lldb) bt
* thread #1, name = 't_hash', stop reason = step over
* frame #0: 0x00005555555554bc t_hash`h_search(hTable=0x0000555555559260, key="400") at myhash.c:134:30
frame #1: 0x0000555555555217 t_hash`main at t_hash.c:14:27
frame #2: 0x00007ffff7dd7ee3 libc.so.6`__libc_start_main + 243
frame #3: 0x00005555555550fe t_hash`_start + 46
(lldb) me read 0x00005555555592e0 -fX -c25 -s8 --force
0x5555555592e0: 0x0000000000000000
0x5555555592e8: 0x0000555555559300
0x5555555592f0: 0x0000555555559320
0x5555555592f8: 0x0000000000000021
0x555555559300: 0x0000000000303034
0x555555559308: 0x0000000000000000
0x555555559310: 0x0000000000000000
0x555555559318: 0x0000000000000021
0x555555559320: 0x0000000000313031
0x555555559328: 0x0000000000000000
0x555555559330: 0x0000000000000000
0x555555559338: 0x0000000000000021
0x555555559340: 0x00005555555592E0
0x555555559348: 0x0000555555559360
0x555555559350: 0x0000555555559380
0x555555559358: 0x0000000000000021
0x555555559360: 0x0000000000303034
0x555555559368: 0x0000000000000000
0x555555559370: 0x0000000000000000
0x555555559378: 0x0000000000000021
0x555555559380: 0x0000000000313031
0x555555559388: 0x0000000000000000
0x555555559390: 0x0000000000000000
0x555555559398: 0x0000000000020C71
0x5555555593a0: 0x0000000000000000
(lldb) me read 0x00005555555592e0 -c256
0x5555555592e0: 00 00 00 00 00 00 00 00 00 93 55 55 55 55 00 00 ..........UUUU..
0x5555555592f0: 20 93 55 55 55 55 00 00 21 00 00 00 00 00 00 00 .UUUU..!.......
0x555555559300: 34 30 30 00 00 00 00 00 00 00 00 00 00 00 00 00 400.............
0x555555559310: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559320: 31 30 31 00 00 00 00 00 00 00 00 00 00 00 00 00 101.............
0x555555559330: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559340: e0 92 55 55 55 55 00 00 60 93 55 55 55 55 00 00 ..UUUU..`.UUUU..
0x555555559350: 80 93 55 55 55 55 00 00 21 00 00 00 00 00 00 00 ..UUUU..!.......
0x555555559360: 34 30 30 00 00 00 00 00 00 00 00 00 00 00 00 00 400.............
0x555555559370: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559380: 31 30 31 00 00 00 00 00 00 00 00 00 00 00 00 00 101.............
0x555555559390: 00 00 00 00 00 00 00 00 71 0c 02 00 00 00 00 00 ........q.......
0x5555555593a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593c0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593d0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
(lldb)
---
lldb) frame variable
(HashTable *) hTable = 0x0000555555559260
(char *) key = 0x0000555555556004 "400"
(size_t) resultHash = 5
(HashNode *) nextValue = 0x00005555555592e0
(char *) keyStrAtIndex =
(char *) keyAtNextValue =
(lldb) fr v
(HashTable *) hTable = 0x0000555555559260
(char *) key = 0x0000555555556004 "400"
(size_t) resultHash = 5
(HashNode *) nextValue = 0x00005555555592e0
(char *) keyStrAtIndex =
(char *) keyAtNextValue =
These are also used as inputs for the command, but will not appear in any of the %-flags. They are separated from regular inputs by use of the '|' character. In effect, these can be used to specify additional inputs to a command that shouldn't appear on the command line. "
By the way flags:
%f The filename from the "inputs" section. This includes the path and extension.
%o The name of the output file(s)
%B Like %b, but strips the extension.
Sample output of monitor

The end strucutre looks like this:
2) lldb - more to the point and in a hurry
* breakpoints can't be set on line number as far as i can tell says it's pending
In either case use br set -n function name or br set -r regex for function name
* n for next , s for step
* br l - list breakpoints
* br del - delete them
* me read
-fX for hex uppercase -c25 25 lines I think -s8 - for bytes 8 bytes --force if it says it does not display more than 1024 bytes of memory
* bt to view stack
* frame variables to view what varaibles were assigned and their entry points
(lldb)
Process 27249 stopped
* thread #1, name = 't_hash', stop reason = step over
frame #0: 0x00005555555554bc t_hash`h_search(hTable=0x0000555555559260, key="400") at myhash.c:134:30
131 else {
132 // looking for the key inside the next element of the linked list
133 char* keyAtNextValue = hTable->h_items[resultHash]->h_next->h_key;
-> 134 while( nextValue->h_next != NULL) {
135 fprintf(stderr, "Found a collision, traversing Linked list at address %p, key is: %s",
136 nextValue, nextValue);
137 nextValue += 1;
(lldb) print nextValue
(HashNode *) $0 = 0x00005555555592e0
(lldb) br l
Current breakpoints:
1: name = 'h_search', locations = 1, resolved = 1, hit count = 1
1.1: where = t_hash`h_search + 17 at myhash.c:97:39, address = 0x0000555555555401, resolved, hit count = 1
(lldb) print *nextValue
(HashNode) $1 = {
h_next = 0x0000000000000000
h_key = 0x0000555555559300 "400"
h_value = 0x0000555555559320 "101"
}
(lldb) print *nextValue->h_next
error: Couldn't apply expression side effects : Couldn't dematerialize a result variable: couldn't read its memory
(lldb) print nextValue->h_next
(HashNode *) $3 = 0x0000000000000000
(lldb) print *nextValue->h_key
(char) $4 = '4'
(lldb) print nextValue->h_key
(char *) $5 = 0x0000555555559300 "400"
(lldb) bt
* thread #1, name = 't_hash', stop reason = step over
* frame #0: 0x00005555555554bc t_hash`h_search(hTable=0x0000555555559260, key="400") at myhash.c:134:30
frame #1: 0x0000555555555217 t_hash`main at t_hash.c:14:27
frame #2: 0x00007ffff7dd7ee3 libc.so.6`__libc_start_main + 243
frame #3: 0x00005555555550fe t_hash`_start + 46
(lldb) me read 0x00005555555592e0 -fX -c25 -s8 --force
0x5555555592e0: 0x0000000000000000
0x5555555592e8: 0x0000555555559300
0x5555555592f0: 0x0000555555559320
0x5555555592f8: 0x0000000000000021
0x555555559300: 0x0000000000303034
0x555555559308: 0x0000000000000000
0x555555559310: 0x0000000000000000
0x555555559318: 0x0000000000000021
0x555555559320: 0x0000000000313031
0x555555559328: 0x0000000000000000
0x555555559330: 0x0000000000000000
0x555555559338: 0x0000000000000021
0x555555559340: 0x00005555555592E0
0x555555559348: 0x0000555555559360
0x555555559350: 0x0000555555559380
0x555555559358: 0x0000000000000021
0x555555559360: 0x0000000000303034
0x555555559368: 0x0000000000000000
0x555555559370: 0x0000000000000000
0x555555559378: 0x0000000000000021
0x555555559380: 0x0000000000313031
0x555555559388: 0x0000000000000000
0x555555559390: 0x0000000000000000
0x555555559398: 0x0000000000020C71
0x5555555593a0: 0x0000000000000000
(lldb) me read 0x00005555555592e0 -c256
0x5555555592e0: 00 00 00 00 00 00 00 00 00 93 55 55 55 55 00 00 ..........UUUU..
0x5555555592f0: 20 93 55 55 55 55 00 00 21 00 00 00 00 00 00 00 .UUUU..!.......
0x555555559300: 34 30 30 00 00 00 00 00 00 00 00 00 00 00 00 00 400.............
0x555555559310: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559320: 31 30 31 00 00 00 00 00 00 00 00 00 00 00 00 00 101.............
0x555555559330: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559340: e0 92 55 55 55 55 00 00 60 93 55 55 55 55 00 00 ..UUUU..`.UUUU..
0x555555559350: 80 93 55 55 55 55 00 00 21 00 00 00 00 00 00 00 ..UUUU..!.......
0x555555559360: 34 30 30 00 00 00 00 00 00 00 00 00 00 00 00 00 400.............
0x555555559370: 00 00 00 00 00 00 00 00 21 00 00 00 00 00 00 00 ........!.......
0x555555559380: 31 30 31 00 00 00 00 00 00 00 00 00 00 00 00 00 101.............
0x555555559390: 00 00 00 00 00 00 00 00 71 0c 02 00 00 00 00 00 ........q.......
0x5555555593a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593c0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x5555555593d0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
(lldb)
---
lldb) frame variable
(HashTable *) hTable = 0x0000555555559260
(char *) key = 0x0000555555556004 "400"
(size_t) resultHash = 5
(HashNode *) nextValue = 0x00005555555592e0
(char *) keyStrAtIndex =
(char *) keyAtNextValue =
(lldb) fr v
(HashTable *) hTable = 0x0000555555559260
(char *) key = 0x0000555555556004 "400"
(size_t) resultHash = 5
(HashNode *) nextValue = 0x00005555555592e0
(char *) keyStrAtIndex =
(char *) keyAtNextValue =